Hadoop的重要特点是数据在数千节点上分区存储和计算,并行执行应用程序的计算。
HDFS和其他分布式文件系统(PVFS、Lustre、GFS)一样,分开存储文件系统元信息(NameNode)和应用程序数据(DataNodes),服务器之间通过基于TCP的协议通信。
DataNodes没有和PVFS一样使用数据保护机制(如RAID)来使文件持久存放,而是像GFS一样在多个DataNode冗余存放文件内容来实现可靠性。保证持久存放的同时也可以加速传输数据。
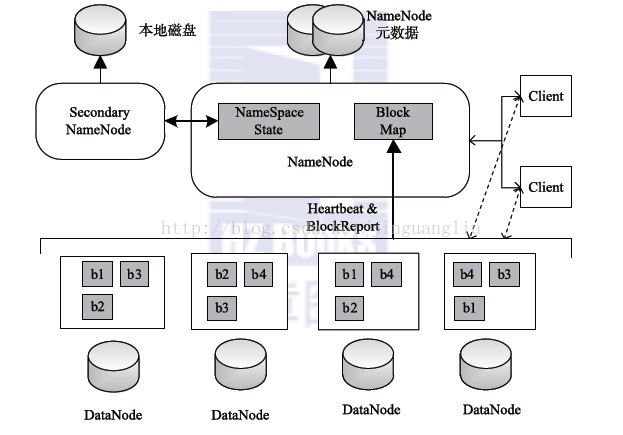
HDFS总体上采用了master/slave架构,主要由以下几个组件构成:Client、NameNode、Secondary NameNode和DataNode。
NameNode管理文件系统的命名空间,维护文件系统树及整棵树内所有的文件和目录。这些信息以两个文件形式永久保存在本地磁盘上:命名空间镜像文件fsimage和编辑日志edits文件。NameNode也记录着每个文件中各个块所在的数据节点信息,但它并不永久保存块的位置信息,因为这些信息会在系统启动时由数据节点重建。
Secondary NameNode最重要的任务并不是为NameNode元数据进行热备份,而是定期合并fsimage和edits日志,并传输给NameNode。这里需要注意的是,为了减少NameNode的压力,NameNode并不会自己合并fsimage和edits,而是将文件存储到磁盘上,交由Secondary NameNode完成。
DataNode是文件系统的工作节点。它们根据需要存储并检索数据块(受客户端或NameNode调度),并且定期向NameNode发送它们所存储的块的列表。
客户端(client)代表用户通过与NameNode和DataNode交互来访问整个文件系统。客户端提供一个类似于POSIX的文件系统接口,因此用户在编程时无需知道NameNode和DataNode也可以实现其功能。
NameNode
HDFS命名空间是文件和目录的层级结构。文件和目录在NameNode上通过inodes表示,inodes记录了各种属性如:权限、修改和访问次数、命名空间、磁盘空间配额。
DataNodes
DataNode中的每个块副本通过两个原生文件来表示,一个包含数据本身,另一个是文件元数据(包括块数据校验和、块生成戳 generation stamp)。数据文件的大小等于实际块长度,不需要额外空间舍入到传统文件系统中的名义块大小,因此如果块是半满的,就在本地占一半的空间。
HDFS Client
用户应用程序通过HDFS客户端访问文件系统,这是一个程序库,开放了HDFS文件系统接口。
Image and Journal
命名空间的image就是文件系统的元数据,将应用数据以目录和文件的形式组织。一条被写入的image持久化记录叫做checkpoint。journal是提前写入的提交日志,是必须被持久化的文件系统修改情况。对于每个客户端启动的事务,所做的修改被记录在journal中,journal文件会在更改提交到HDFS客户端前刷新和同步。
CheckpointNode
HDFS的NameNode除了服务客户端之外,还可以扮演另外两个角色之一,即CheckpointNode或BackupNode,这在启动时指定。
BackupNode
和CHeckpointNode类似,BackupNode也有能力创建定期检查点,但除此之外还在内存中维护文件系统命名空间最新的image,这总是和NameNode的状态一起同步
Upgrades, File System Snapshots
在软件升级的时候,由于软件bug或人犯错导致系统崩溃的可能性会增加。在HDFS中创建快照的目的就是在升级期间,使对保存在系统中数据的潜在损伤最小化。
2.2 论文核心算法
The Hadoop Distributed File System (Yahoo!)笔记 - 知乎
HDFS(Hadoop Distributed File System)简介_Bob Liu的…_…
这两个笔记我觉得写的挺好的,可以看看。
当应用程序读一个文件:
- HDFS客户端要求NameNode提供托管文件块副本的DataNode列表,
- 直接联系DataNode,并请求需要传送的块
当客户端写文件:
- 要求NameNode选择几个DataNode托管第一个文件块的副本
- 客户端组织node-to-node流水线,并传送数据
- 当第一个块填入后,客户端要求新的DataNodes来托管下一个块的副本
- 组织新的流水线,传送数据,每次倾向选择不同的DataNodes
客户端、NameNode、DataNodes的交互如下图:
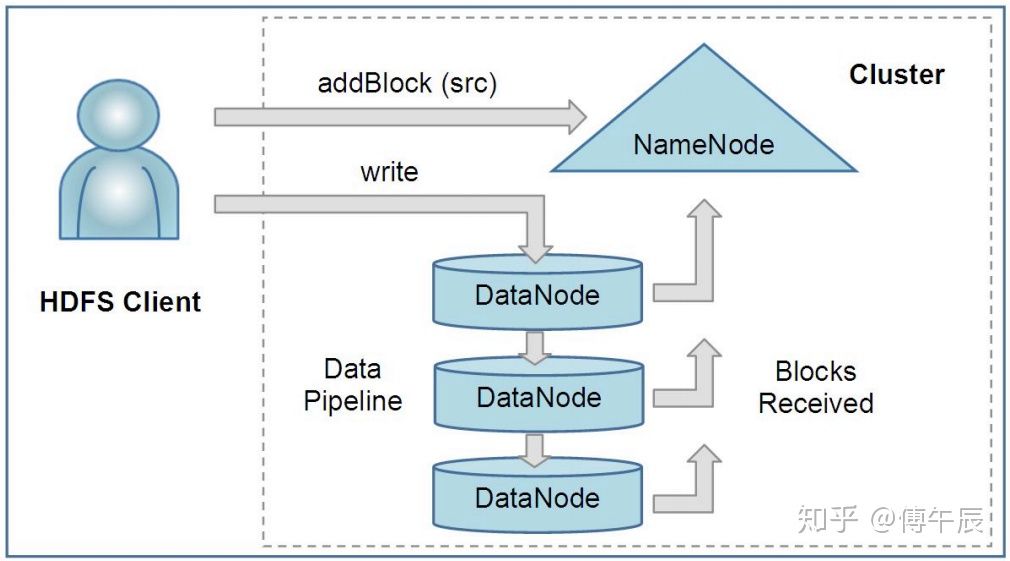
客户端通过把路径传给NameNode来创建一个新文件,NameNode为文件的每个块返回DataNode列表来托管块的副本。客户端然后通过流水线把数据传给选定的DataNodes,这些DataNodes最终将创建块副本的确认信息告诉NameNode。
一个HDFS文件是由块组成的。需要新块时,NameNode会分配一个具有unique block ID的块,并且决策出一个DataNodes列表来处理块副本。DataNodes组成一个管道,其顺序使客户端到最后一个DataNode的总网络距离最小。字节作为分组序列(sequence of packets)被推入流水线。应用程序在客户端写入第一个缓冲区,填充完一个缓冲区(通常64KB)后,数据被推送到流水线。在接收到先前数据包的确认信息之前,可以将下一个分组推送到流水线。未完成分组的数量受客户端未完成分组的窗口大小的限制。
在数据被写入HDFS文件后,HDFS不保证数据对新reader可见,直到文件被关闭。如果用户应用需要这种可见性保证,可以显式调用 hflush 操作。这样当前的分组会立即推送到流水线,hflush操作会等待所有的DataNode确认已经成功传输了分组。所有之前写入的数据就会理所应当地对reader可见。
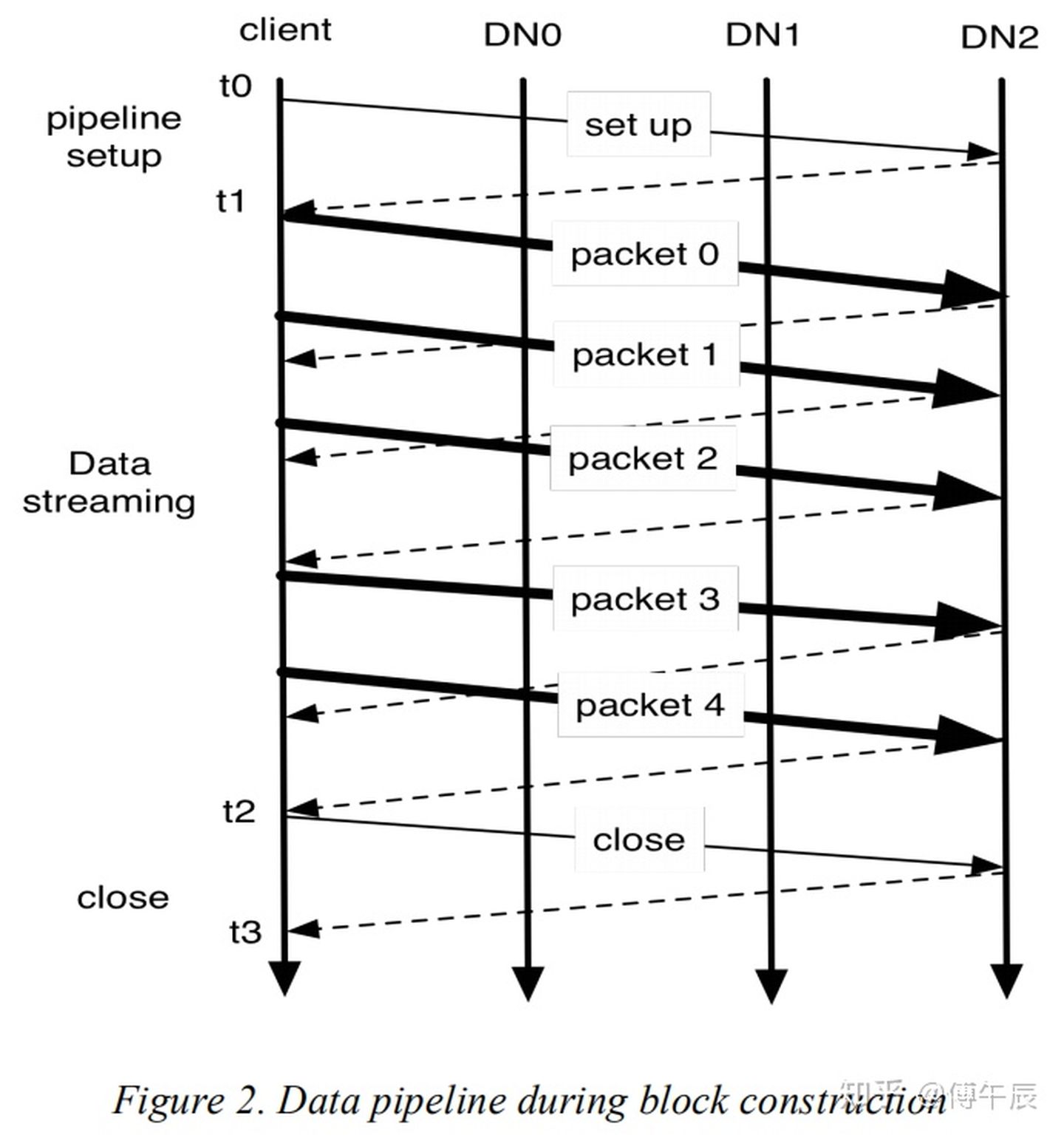
如果没有错误发生,block construction会像上图一样发生。图2展示了一个有三个DataNodes的管道和5个分组的块。粗线表示数据分组,虚线表示确认信息,细线表示设置和关闭流水线的控制信息。垂直线表示客户端和三个DataNode的活动,时间从上到下依次进行。t0到t1是流水线设置阶段。t1到t2是数据流阶段,t1是首次传输分组的时间,t2是收到最后一个分组确认信息的时间。这里hflush操作将传输第二个分组。hflush指示数据分组传输不是一个分离的操作。t2到t3是流水线关闭阶段。
2021/7

