研究是因为有趣
Deep Q-Learning with Keras and Gym · Keon’s Blog
Deep Q Learning,DRL-QoS Cloud Scheduling代码已跑通,AIRL未跑,回过头来重新逐行深入分析理解及复现,以便之后独立使用。
1 | conda info -e #(查看所有的虚拟环境) |
环境搭建
| 目录 | 名称 | 本机版本号 | 命令或备注 |
|---|---|---|---|
| python | anaconda | ok | |
| python | ok | ||
| pip,conda换源 | ok | 尽量用conda和anaconda安装,少用pip | |
| 虚拟环境 | ok | activate xx ;deactivate | |
| pycharm | |||
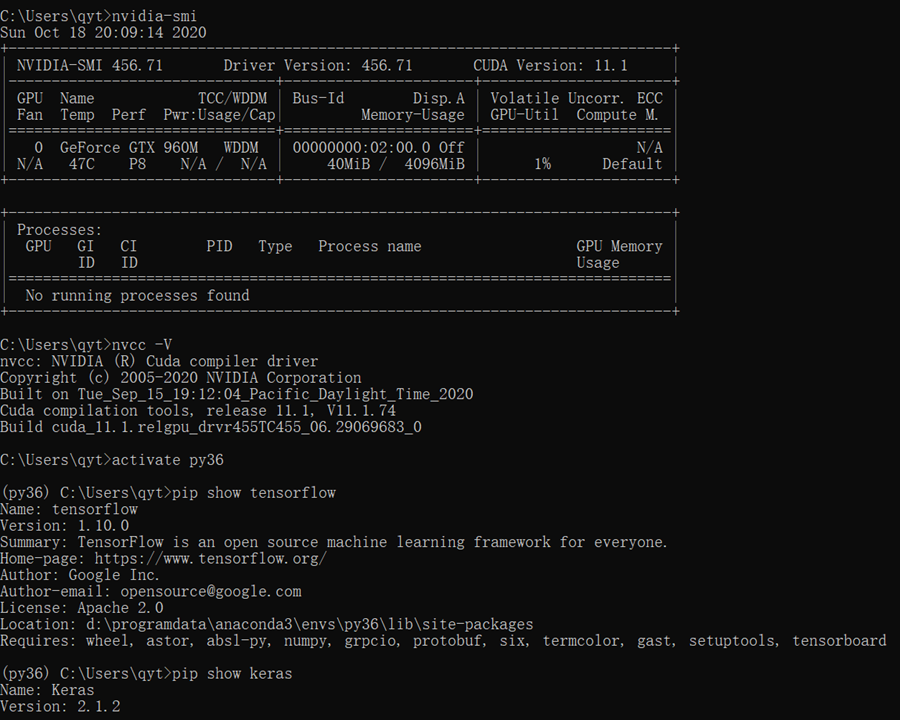
| GPU驱动 | GPU | 456.71 | nvidia-smi |
| GPU加速 | cuda | 11.1.96 | nvcc -V |
| cuDNN | GUDA,CUDNN,PY, | ||
| 框架 | opencv | ||
| tensorflow | 版本容易与keras冲突 | ||
| pytorch | |||
| 步骤 | https://blog.csdn.net/qq_26412763/article/details/90272491 | ||
| 冲突关系 | tensorflow | keras | https://docs.floydhub.com/guides/environments/ |
| gpu驱动 | CUDA | cuDNN | 先更新显卡驱动,然后下载对应的CUDA,国内ip无法下载官网CUDA包,成功后会秒变1kb |
Deep Q Learning
1 | tensorflow == 1.10.0 |
1 | # -*- coding: utf-8 -*- |
深度学习常见的优化方法(Optimizer)总结:Adam,SGD,Momentum,AdaGard等
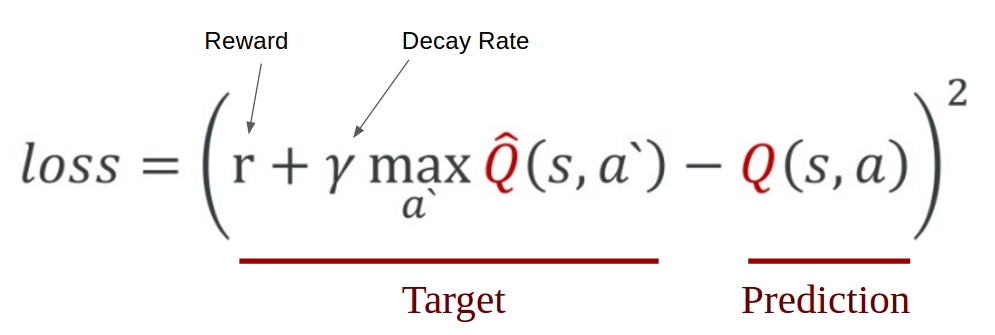
图TD中的LOSS
安装Gym后,一般的使用流程是:
加载 gym 库:
import gym进入指定的实验环境:
env = gym.make("Taxi-v2").env渲染环境,即可视化看看环境的样子:
env.render()
其中 env 是 gym 的核心接口,有几个常用的方法也是实验中通用的:
env.reset, 重置环境,返回一个随机的初始状态。env.step(action),将选择的action输入给env,env 按照这个动作走一步使环境进入下一个状态,所以它的返回值有四个:
1 | next_state, reward, done, _ = env.step(action) |
observation:进入的新状态
reward:采取这个行动得到的奖励
done:当前游戏是否结束
info:其他一些信息,如性能表现,延迟等等,可用于调优
env.render,这个前面说过可以可视化展示环境
注意到,在 state1-action-state2 这个过程中,action 是需要我们决定的,通常会通过 greedy search 和 q learning 等算法选择,而 state1,state2 就可以用 env 自动获取。
gym模块中环境的常用函数
gym的初始化
1 | env = gym.make('CartPole-v0') |
gym的各个参数的获取
1 | env.action_space |
刷新环境
1 | env.reset() |
读取环境
1 | observation_, reward, done, info = env.step(action) |
2020/12/28

